Split-Level I/O Scheduling
For my CS854 class I have to read a trio of research papers each week, and post summaries, which are then updated after the class that a student gives a presentation on it. Don't rely on my summaries for anything, but it might interest some of you, so I'm posting it here.
Just read the paper.
This paper introduces the idea of split-level I/O scheduling. This tries to gather the most useful information possible, and use it to build a better I/O scheduler. It splits the scheduling logic across handlers at three layers of the storage stack: block, system call, and page cache.
There are a number of different policies that we could be trying to implement:
- Fairness
- Performance
- Isolation
These are all different goals, and require different things from a scheduler.
Lets take a look at the IO stack. It looks something like this: 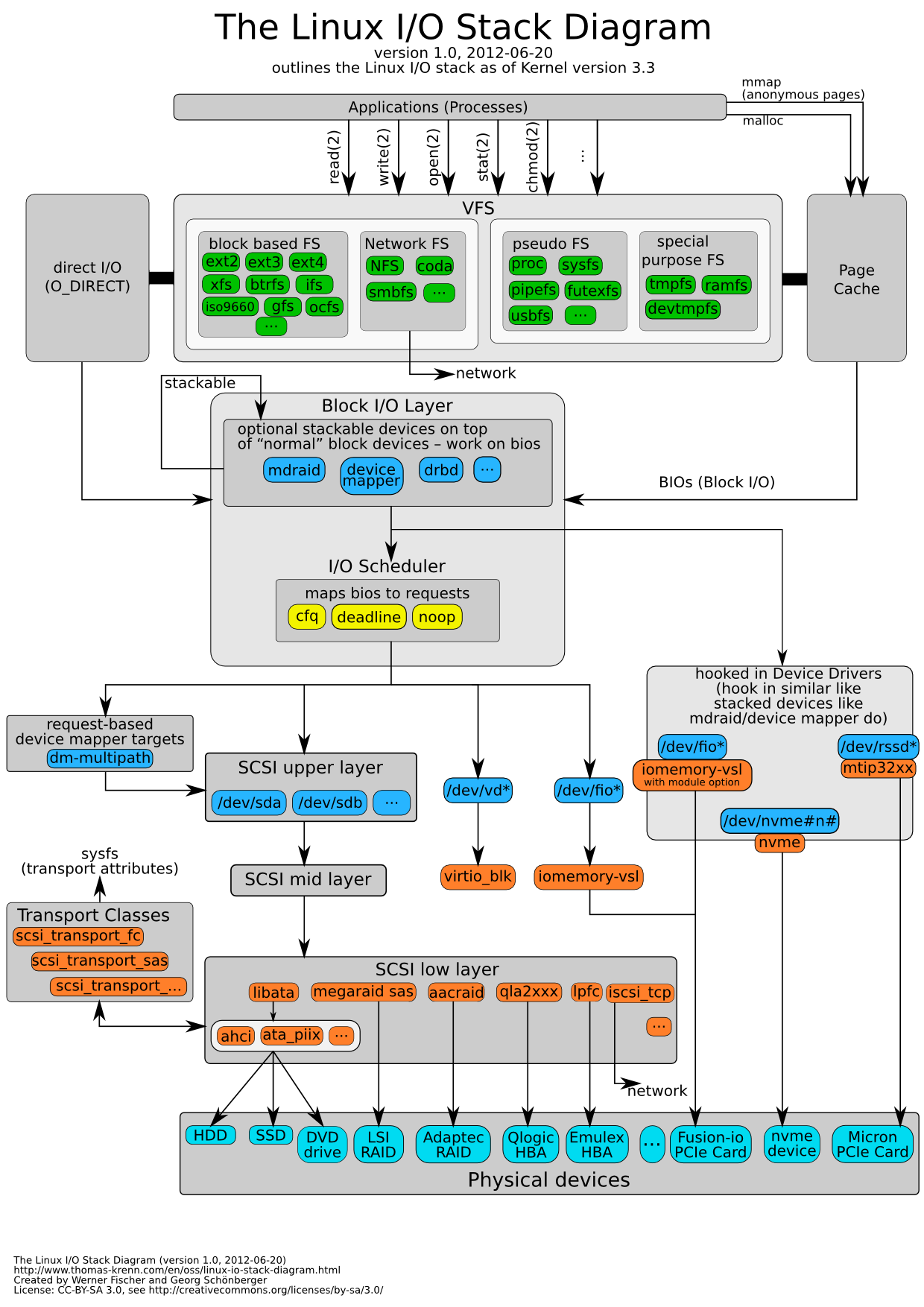 Which I took from thomas-krenn.com, created by Werner Fischer.
Which I took from thomas-krenn.com, created by Werner Fischer.
The major parts are
- System Call Interface
- Virtual File System
- Page Cache
- Block Layer IO
- Device Drivers
Let us first consider what classic schedulers are like. There has been a lot of classic work, for example consideration of how the disk head moves on a hard drive, and re-arranging blocks to be written to minimize seek time.
There are two downsides to working at just the block level. The file system mandates that some requests are not re-ordered because they are critical to preserve consistency in case of a crash. This means that by the time the requests are hit the scheduler, it's too late for the scheduler to have a say. The second is that the scheduler has no information about what process is making a request, so it cannot do proper accounting.
One way to fix those two problems is the place the scheduler above the file system, at the system call level. This will fix those two problems, but runs into other ones. In particular, the system-call level scheduler will not know about the page cache, nor other information that would help when trying to schedule tasks most efficiently. Also, the file system will issue metadata requests and journaling writes, so one I/O request can multiply after the system call level, making it hard to accurately estimate costs.
So, why not both?

The idea is to implement handlers at the system call, page-cache, and block layers, so we can get the benefits of both kinds of handlers. One downside would be the added complexity, as well as some small overhead.
The system call level handlers can tag the I/O operation with the process that will be billed for it, while we still have a block level scheduler that can use that information to properly handle priority levels.
This is called Cause Mapping, and it lets us implement fairness properly. Without it, we can get things like this:
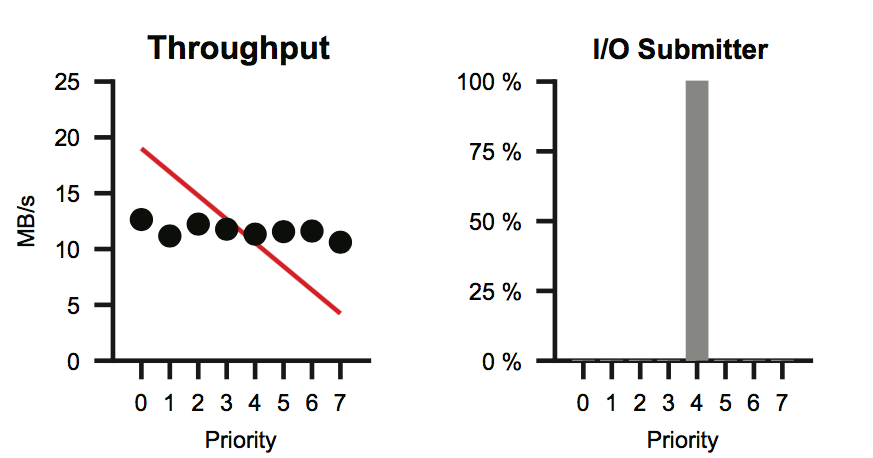
where the priority of the task doesn't matter, as all the IO comes from a writeback thread.
Writes aren't always written to disk immediately, often the changes stay in the page cache for a while. (This makes a lot of sense for things like mmap'd pages, where you are changes bytes at a time. I'm not entirely sure about when you're just appending to a file over and over again if the IO is buffered in the same way.)
The OS just tracks which pages are "dirty", in that they don't match what's on disk, and periodically has a background thread write the dirty pages to disk.
What's happening in that example with the CFQ is that all the dirty pages are being actually written to disk by this background thread, and the block level scheduler only sees a bunch of writes by the same thread. That leads to the failure of fairness.
The Cause Mapping introduced at the system call level scheduler can be used to solve this problem, making the split-level schedulers better in this respect.
Another problem solved is that of cost estimation, since the system call level scheduler has no idea if the reads/writes are going to just be absorbed by the page cache, or have to go all the way to disk, so it's hard to be completely fair. Also, write amplification (the transaction overhead, for example) also obscures how expensive each operation will be too.
But by the time the requests make it to the block level scheduler, it's much easier to predict the cost of the operations. (Of course, it'd be even easier to judge from the hard disk controller directly, but that's a bit too late to be useful, since the operation would have already been scheduled at that point.) At the block level, a scheduler is less likely to overestimate the cost (due to a cache hit), nor underestimate the cost (journaling), and is much more accurate.
Unfortunately, the block level scheduler could be too late to affect anything (i.e. preform reordering), as writes can be buffered for 30 seconds before being flushed and thus exposed to the block level scheduler, at which point there isn't much it can do about it.
This system starts off with a guess at the systemcall layer, and refines it as more information becomes available.